In order to calculate percentage and cumulative percentage of column in pyspark we will be using sum() function and partitionBy(). We will explain how to get percentage and cumulative percentage of column by group in Pyspark with an example for each.
- Calculate Percentage of column in pyspark : Represent the value of the column in terms of percentage
- Calculate cumulative percentage of column in pyspark
- Cumulative percentage of the column by group
- Calculate Cumulative percentage of the column by group
- Sort and find the cumulative sum of the column in pyspark
We will use the dataframe named df_basket1.
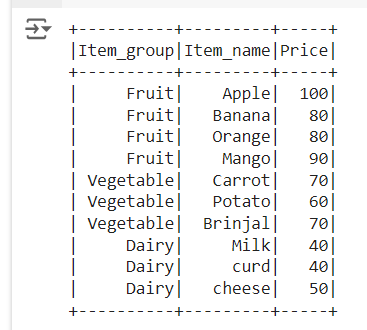
Calculate percentage of column in pyspark : Method 1
Sum() function and partitionBy() is used to calculate the percentage of column in pyspark
import pyspark.sql.functions as f
from pyspark.sql.window import Window
df_percent = df_basket1.withColumn('price_percent',f.col('Price')/f.sum('Price').over(Window.partitionBy())*100)
df_percent.show()
We use sum function to sum up the price column and partitionBy() none to calculate percentage of column as shown below

Calculate percentage of column in pyspark: Method 2 using collect()
Here’s how you can calculate the percentage of values in a column in pyspark with collect() function
# Calculate total sum of the column
total_sum = df_basket1.select(sum(col("Price"))).collect()[0][0]
# Calculate the percentage of each value in the column
df_with_percentage = df_basket1.withColumn("percentage", (col("Price") / total_sum) * 100)
df_with_percentage.show()
- sum(col(“value”)) calculates the total sum of the column.
- col(“value”) / total_sum computes the fraction of each value relative to the total sum.
- Multiplying by 100 gives the percentage.
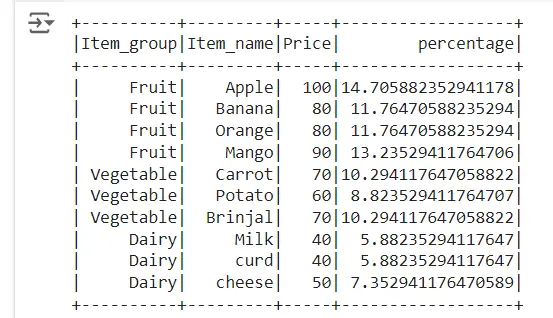
Calculate percentage of column by group in pyspark
Sum() function and partitionBy() is used to calculate the percentage of column by group in pyspark
import pyspark.sql.functions as f
import sys
from pyspark.sql.window import Window
df_percent_group = df_basket1.withColumn('price_percent_by_group', f.col('Price')/f.sum('Price').over(Window.partitionBy('Item_group'))*100)
df_percent_group.show()
We use sum function to sum up the price column and partitionBy() function to calculate percentage of column as shown below and we name it as “price_percent_by_group”.
output:
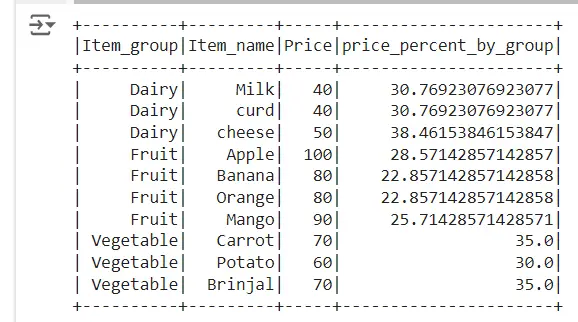
Calculate cumulative percentage of column in pyspark
In order to calculate cumulative percentage of column in PySpark we will be using sum() function and partitionBy(). We will explain how to get cumulative percentage of column by group in Pyspark with an example.

Sum() function and partitionBy() is used to calculate the percentage of column in pyspark
import pyspark.sql.functions as f
import sys
from pyspark.sql.window import Window
df_percent = df_basket1.withColumn('price_percent',f.col('Price')/f.sum('Price').over(Window.partitionBy())*100)
df_cum_percent = df_percent.withColumn('cum_percent', f.sum(df_percent.price_percent).over(Window.partitionBy().orderBy().rowsBetween(-sys.maxsize, 0)))
df_cum_percent.show()
We use sum function to sum up the price column and partitionBy() function to calculate percentage of column as shown below and we name it as price_percent. Then we sum up the price_percent column to calculate the cumulative percentage of column
Output:

Calculate cumulative percentage of column in pyspark: Method 2 – sort and find the cumulative sum
Here’s how you can calculate the cumulative percentage of a column in pyspark with collect() function
# Define a window ordered by 'value'
window_spec = Window.orderBy("Price").rowsBetween(Window.unboundedPreceding, Window.currentRow)
# Calculate cumulative sum
df = df_basket1.withColumn("cumulative_sum", sum(col("Price")).over(window_spec))
# Calculate total sum of the column
total_sum = df.select(sum(col("Price"))).collect()[0][0]
# Calculate cumulative percentage
df = df.withColumn("cumulative_percentage", (col("cumulative_sum") / total_sum) * 100)
df.show()
Step 1: Define a window function to calculate the cumulative sum :
Window.orderBy(“Price”).rowsBetween(Window.unboundedPreceding, Window.currentRow) defines a window that orders the rows by Price and calculates the cumulative sum up to the current row.
Step 2: Calculate the total sum of the column
sum(col(“Price”)).over(window_spec) calculates the cumulative sum based on the defined window.
The total sum of the value column is computed using df.select(sum(col(“Price”))).collect()[0][0]
Step 3: Divide the cumulative sum by the total sum and multiply by 100 to get the cumulative percentage.
Finally, we compute the cumulative percentage by dividing the cumulative sum by the total sum and multiplying by 100.
Output:
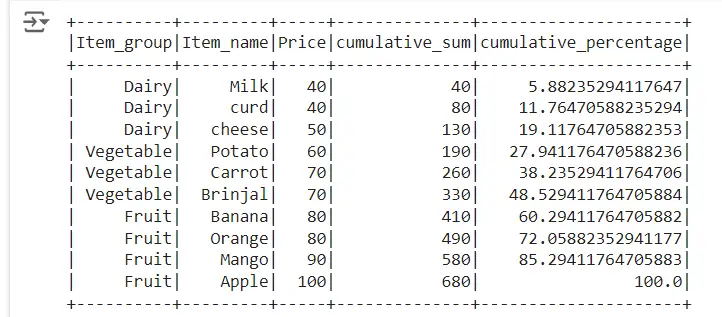
Calculate cumulative percentage of column by group in spark

Sum() function and partitionBy() the column name, is used to calculate the cumulative percentage of column by group.
import pyspark.sql.functions as f
import sys
from pyspark.sql.window import Window
df_percent = df_basket1.withColumn('price_percent', f.col('Price')/f.sum('Price').over(Window.partitionBy('Item_group'))*100)
df_cum_percent_grp = df_percent.withColumn('cum_percent_grp', f.sum(df_percent.price_percent).over(Window.partitionBy('Item_group').orderBy().rowsBetween(-sys.maxsize, 0)))
df_cum_percent_grp.show()
We use sum function to sum up the price column and partitionBy() function to calculate the cumulative percentage of column as shown below and we name it as price_percent. Then we sum up the price_percent column to calculate the cumulative percentage of column by group.


Calculate cumulative percentage of column by group in spark : Method 2
Here’s how you can calculate the cumulative percentage of a column by group in pyspark with collect() function
window_spec = Window.partitionBy("Item_group").orderBy("Price").rowsBetween(Window.unboundedPreceding, Window.currentRow)
# Calculate cumulative sum within each group
df = df_basket1.withColumn("cumulative_sum", sum(col("Price")).over(window_spec))
# Calculate total sum for each group
df = df.withColumn("total_sum", sum(col("Price")).over(Window.partitionBy("Item_group")))
# Calculate cumulative percentage
df = df.withColumn("cumulative_percentage", (col("cumulative_sum") / col("total_sum")) * 100)
df.show()
- partitionBy(“Item_group”).orderBy(“Price”) creates a window that partitions data by the group column and orders by the values within each group.
- sum(col(“Price”)).over(window_spec) calculates the cumulative sum for each group.
- partitionBy(“Item_group”) calculates the total sum of the values in each group.
- The cumulative percentage is calculated by dividing the cumulative sum by the total sum for each group and multiplying by 100.
Output:

Other Related Products:
- Simple random sampling and stratified sampling in pyspark – Sample(), SampleBy()
- Rearrange or reorder column in pyspark
- cumulative sum of column and group in pyspark
- Join in pyspark (Merge) inner , outer, right , left join in pyspark
- Get duplicate rows in pyspark
- Quantile rank, decile rank & n tile rank in pyspark – Rank by Group
- Populate row number in pyspark – Row number by Group
- Percentile Rank of the column in pyspark
- Mean of two or more columns in pyspark
- Sum of two or more columns in pyspark
- Row wise mean, sum, minimum and maximum in pyspark
- Rename column name in pyspark – Rename single and multiple column
- Typecast Integer to Decimal and Integer to float in Pyspark
- Get number of rows and number of columns of dataframe in pyspark
![]()
![]()



")
