Missing values of column in pandas python can be handled either by dropping the missing values or replacing the missing values. Which is listed below in detail.
- drop the rows that have missing values
- Replace missing value with zeros
- Replace missing value with Mean of the column
- Replace missing value with Median of the column
First let’s create a dataframe.
import pandas as pd
import numpy as np
#Create a DataFrame
df1 = {
'Name':['George','Andrea','micheal','maggie','Ravi','Xien','Jalpa',np.nan],
'State':['Arizona','Georgia','Newyork','Indiana','Florida','California',np.nan,np.nan],
'Gender':["M","F","M","F","M","M",np.nan,np.nan],
'Score':[63,48,56,75,np.nan,77,np.nan,np.nan]
}
df1 = pd.DataFrame(df1,columns=['Name','State','Gender','Score'])
print(df1)
So the resultant dataframe will be
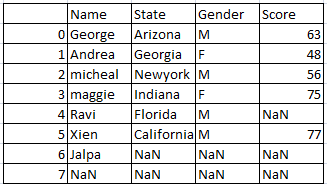
Drop the rows that have missing values
Drop the rows even with single NaN or single missing values.
df1.dropna()
Outputs:

Replace missing value with zeros
Fill the missing values with zeros i.e. replace the missing values with zero
df1.fillna(0)
Outputs:

Replace missing value with Mean of the column:
Fill in the missing values with mean of the column. i.e. replace missing value with mean of the column
df1["Score"].fillna(df1["Score"].mean(), inplace=True)
Output:

Replace missing value with Median of the column:
Fill in the missing values with median of the column. i.e. replace missing value with median of the column
df1["Score"].fillna(df1["Score"].median(), inplace=True)
Output:

![]()
![]()

 function")


")
