Cumulative sum of a column in pandas python is carried out using cumsum() function. Cumulative sum of the column by group in pandas is also done using cumsum() function. row wise cumulative sum can also accomplished using this function. Let’s see how to
- Get the cumulative sum of a column in pandas dataframe in python
- Row wise cumulative sum of the column in pandas python
- Cumulative sum of the column by group in pandas
- cumulative sum of the column with NA values in pandas
Desired Results : cumulative sum of column
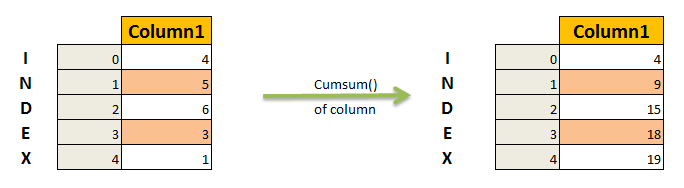
syntax of cumsum() function in pandas:
cumsum(axis= 0|1, skipna=True, *args, **kwargs)
Parameters:
axis: {index or Rows (0), columns (1)}
skipna: Exclude NA/null values. If an entire row/column is NA, the result will be NA
Returns: Cumulative sum of the column
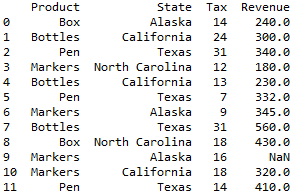
First let’s create a dataframe
import pandas as pd
import numpy as np
data = {'Product':['Box','Bottles','Pen','Markers','Bottles','Pen','Markers','Bottles','Box','Markers','Markers','Pen'],
'State':['Alaska','California','Texas','North Carolina','California','Texas','Alaska','Texas','North Carolina','Alaska','California','Texas'],
'Tax':[14,24,31,12,13,7,9,31,18,16,18,14],
'Revenue':[240,300,340,180,230,332,345,560,430,np.nan,320,410]}
df1=pd.DataFrame(data, columns=['Product','State','Tax','Revenue'])
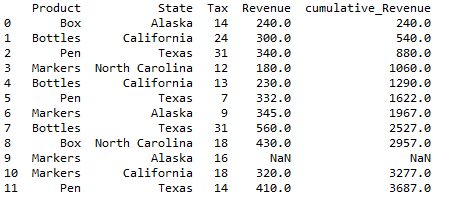
df1
df1 will be
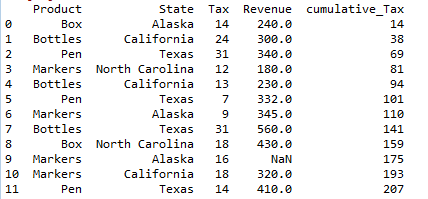
Cumulative sum of a column in a pandas dataframe python:
Cumulative sum of a column in pandas is computed using cumsum() function and stored in the new column namely “cumulative_Tax” as shown below. axis =0 indicated column wise performance i.e. column wise cumulative sum.
### Cumulative sum of a dataframe column df1['cumulative_Tax']=df1['Tax'].cumsum(axis = 0) df1
so resultant dataframe will be
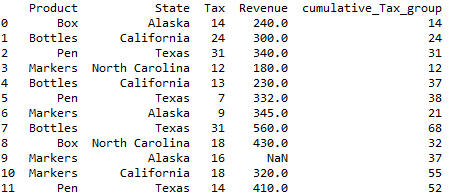
Cumulative sum of a column by group in pandas:
Cumulative sum of a column by group in pandas is computed using groupby() function. along with the groupby() function we will also be using cumulative sum function. And the results are stored in the new column namely “cumulative_Tax_group” as shown below.
### Cumulative sum of the column by group df1['cumulative_Tax_group']=df1.groupby(['Product'])['Tax'].cumsum() df1
so resultant dataframe will be
Cumulative sum of a column with NA values in a pandas dataframe python:
Cumulative sum of a column in pandas with NA values is computed and stored in the new column namely “cumulative_Revenue” as shown below. by default NA values will be skipped and cumulative sum is calculated for rest
### cumulative sum of the column with NA df1['cumulative_Revenue']=df1.Revenue.cumsum(axis = 0) df1
so resultant dataframe will be
Desired Results : Row wise cumulative sum.
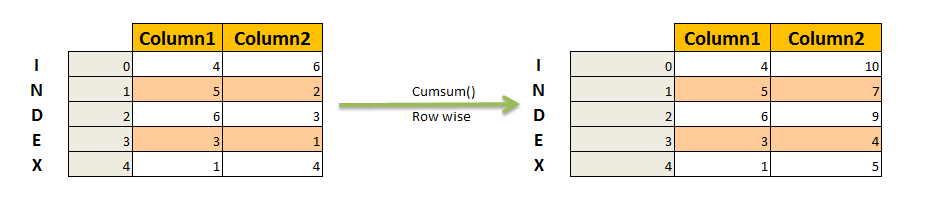
Row wise Cumulative sum of dataframe in pandas:
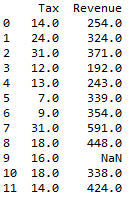
Cumulative sum of a row in pandas is computed using cumsum() function and stored in the “Revenue” column itself. axis =1 indicated row wise performance i.e. row wise cumulative sum.
### Cumulative sum of the column by group df1[['Tax','Revenue']].cumsum(axis=1)
so resultant dataframe will be
Other Related Topics:
- Cumulative product of column in pandas python
- Cumulative percentage of a column in pandas python
- Difference of two columns in pandas dataframe – python
- Sum of two or more columns of pandas dataframe in python
- Sort column in pandas dataframe python
- Groupby sum in pandas dataframe python
- Groupby count in pandas dataframe python
- Groupby mean in pandas dataframe python
further details about cumsum() function is in documentation.
![]()
![]()



